ZienkiFlowNet — Un réseau de neurones sur graphes pour la simulation d'écoulements 2D
Construire un modèle de substitution rapide pour la CFD : architecture GNN double-branche, biais physiques et entraînement sur 85 cas seulement.
Prédire un écoulement fluide dans une géométrie complexe est l'une des tâches les plus coûteuses en ingénierie. Les solveurs CFD classiques sont précis, mais demandent des minutes de calcul pour chaque nouvelle géométrie. ZienkiFlowNet s'attaque à ce problème : un réseau de neurones sur graphes qui apprend à prédire les champs de vitesse et de pression directement à partir de la géométrie, en remplaçant des minutes de CFD par quelques millisecondes d'inférence.
1. Le problème
On considère des écoulements visqueux incompressibles à travers des conduits 2D de géométrie variable. Chaque conduit est défini par sa largeur , sa longueur d'axe , et son nombre de coudes (0 à 3). L'écoulement est piloté par une chute de pression imposée entre l'entrée et la sortie.

Pour une nouvelle géométrie, le modèle prédit :
- Le champ de vitesse à chaque nœud du maillage
- Le champ de pression à chaque nœud
- Le débit volumique d'entrée
La vitesse de référence est donnée par la solution de Poiseuille pour un conduit droit de même largeur et longueur :
2. Le jeu de données
La base d'entraînement comporte 100 géométries paramétriques de conduits 2D générées avec le solveur EF Zienki. Chaque cas comprend :
- Un maillage triangulaire P1 (1 000 à 5 000 nœuds)
- Une largeur entre 0,1 et 0,5 m
- 0 à 3 coudes à divers angles
- Propriétés fluides fixes : Pa·s, kg/m³
- Chute de pression Pa
Le jeu est partitionné 85/15 entre entraînement et validation, soit 85 cas d'entraînement et 15 de validation couvrant une large gamme de complexité géométrique, du canal droit à la configuration à trois coudes.
3. Les features d'entrée
Chaque nœud du maillage est décrit par un vecteur de features de dimension 12 :
| Feature | Description |
|---|---|
coord_x, coord_y | Coordonnées du nœud |
d_wall | Distance au mur le plus proche |
d_wall / (w/2) | Distance au mur normalisée |
s / L | Position d'abscisse curviligne (0→1) |
is_inlet | Indicateur binaire : entrée |
is_outlet | Indicateur binaire : sortie |
is_wall | Indicateur binaire : paroi |
geo_inlet | Distance géodésique depuis l'entrée |
geo_outlet | Distance géodésique depuis la sortie |
flow_tangent_x | Direction locale d'écoulement (x) |
flow_tangent_y | Direction locale d'écoulement (y) |
Les distances géodésiques sont calculées par un Dijkstra multi-sources sur le graphe du maillage. La tangente d'écoulement est le gradient de la distance géodésique à l'entrée, calculé avec les fonctions de base éléments finis P1 puis normalisé. Cela fournit une direction d'écoulement bulk, lisse et consciente de la géométrie.
Les features d'arêtes (dimension 7) encodent le déplacement relatif, les projections sur la normale au mur, et le type d'arête (maillage ou raccourci virtuel sur la ligne médiane).
Les features globales (dimension 8) encodent les paramètres physiques : largeur, longueur totale, nombre de coudes, viscosité, densité, chute de pression et vitesse de référence.
4. Architecture
ZienkiFlowNet utilise un réseau de neurones sur graphes à double branche, opérant directement sur le maillage triangulaire non structuré :

Composants clés
a) Blocs MeshGraphNet (MGNBlock) — Des MLPs au niveau des arêtes calculent les messages à partir des triplets (source, destination, arête). Les états des nœuds sont mis à jour par agrégation avec connexions résiduelles.
b) CellBlock (passage de messages éléments-finis) — Les messages sont échangés à l'intérieur de chaque triangle en utilisant les états des trois sommets et un vecteur d'état de cellule. Cela mime l'assemblage EF P1 et capture la physique au niveau de l'élément.
c) Attention frontière avec encodage positionnel relatif — Chaque nœud effectue une cross-attention sur les nœuds de frontière (entrée, sortie, paroi). Un biais positionnel relatif appris encode , permettant au modèle de « savoir » à quelle distance et dans quelle direction se trouvent les conditions aux limites.
d) Encodage positionnel Laplacien (32-dim) — Deux variantes concaténées :
- Neumann (16-dim) : encode la connectivité du maillage
- Dirichlet (16-dim) : encode la topologie multi-parois en imposant des conditions aux limites nulles sur les murs
e) Conception double-branche — La branche champ utilise un GraphUNet avec coarsening basé sur METIS (2 niveaux) pour la propagation spatiale longue portée — essentielle pour transmettre l'information de pression à travers les coudes. La branche scalaire est une tour plate de 4 couches MGN qui se concentre sur l'extraction de features fines aux frontières pour le débit .
f) Token Query Head — Un token de requête apprenable effectue une cross-attention sur toutes les features de nœuds pour produire la sortie scalaire , découplant la prédiction de champ de l'estimation de grandeur globale.
g) Repères locaux équivariants — Aux nœuds de paroi, la vitesse est décomposée en composantes tangentielle et normale via des normales de mur lissées. Cela rend le modèle invariant aux rotations globales de la géométrie.
Le modèle compte environ 750 000 paramètres avec une dimension cachée de 96, 8 couches de passage de messages et 4 têtes d'attention.
5. Stratégie d'entraînement
Entraîner ZienkiFlowNet est un exercice délicat : avec seulement 85 cas, le modèle doit extraire un maximum d'information de chaque échantillon tout en évitant le sur-apprentissage. On combine quatre stratégies : auto-supervision masquée à la JEPA, pertes informées par la physique calculées avec la base EF, projection dure des conditions aux limites, et un planning d'optimisation soigneusement réglé.
a) Auto-supervision masquée style JEPA
Inspiré des Joint Embedding Predictive Architectures, chaque pas d'entraînement sélectionne aléatoirement une fraction des nœuds du maillage comme « cibles » (à prédire), tandis que les autres servent de « contexte » (observations visibles). Le modèle reçoit toute la géométrie et les conditions aux limites, mais ne voit les champs solutions qu'aux nœuds de contexte, et doit reconstruire les champs aux nœuds cibles masqués.
Le taux de masquage suit un planning cosinus de 30 % à 100 % sur les 120 époques d'entraînement :
Au début, le modèle voit 70 % de la solution et comble de petits trous — une tâche d'interpolation facile qui amorce l'apprentissage. Au fil de l'entraînement, de moins en moins de nœuds sont révélés, jusqu'à ce que le modèle doive prédire le champ entier à partir de la seule géométrie (masquage à 100 % = mode inférence pure). Cet effet de curriculum opère une transition douce de l'interpolation à la prédiction complète.
Crucialement, les nœuds frontière (entrée, sortie, paroi) sont toujours inclus dès que le taux de masquage dépasse 50 %, assurant que le modèle n'a jamais à halluciner les conditions aux limites.
b) Perte multi-composantes informée par la physique
La perte totale combine cinq termes, chacun visant un aspect différent de la justesse physique :
- — MSE sur les nœuds : erreur sur aux nœuds cibles masqués. La pression est pondérée 1,5× par rapport à la vitesse pour compenser son ordre de grandeur typiquement plus faible.
- — MSE sur le débit : erreur sur le débit volumique scalaire d'entrée . Force le Token Query Head à apprendre la relation intégrale entre géométrie et débit global.
- — Résidu des conditions aux limites : pénalise les violations du non-glissement ( aux parois) et des conditions de Dirichlet sur la pression ( en entrée, en sortie). Contrainte molle en plus de la projection dure.
- — Pénalité de divergence : par triangle, calculé exactement avec les gradients des fonctions de base P1 (pas par différences finies). Impose l'incompressibilité.
- — Correspondance de vorticité : la vorticité par triangle est comparée à la vorticité de référence. Également calculée avec les gradients de base P1. Cette supervision au niveau dérivé affine les structures d'écoulement autour des coudes.
Le calcul EF-exact de et est un choix de conception crucial : en utilisant les mêmes fonctions de base P1 que le solveur CFD ayant généré les données, ces pertes sont numériquement cohérentes avec la discrétisation du maillage — pas de lissage spatial, pas d'artefacts d'interpolation.
c) Projection dure des conditions aux limites
Après que le modèle a produit sa prédiction dans l'espace normalisé, une projection dure est appliquée avant le calcul de la perte et à l'inférence :
- Nœuds de paroi : (non-glissement)
- Nœuds d'entrée : (pression imposée)
- Nœuds de sortie : (pression de référence)
Cela garantit que les conditions aux limites sont exactement satisfaites quelle que soit la sortie du réseau, et concentre la capacité du réseau sur la prédiction du champ intérieur.
d) Planning d'optimisation
- AdamW : lr , weight_decay
- Warmup linéaire sur 5 époques (lr × 0,01 → lr × 1,0)
- Annealing cosinus de l'époque 5 à l'époque 120
- Gradient clipping à 1,0
- Batch size : 8 graphes
- Sélection du meilleur checkpoint sur val v_rel + p_rel
L'entraînement tourne en environ 2 heures sur CPU (pas de GPU nécessaire) grâce à la taille modeste du jeu de données (85 graphes, ~3000 nœuds chacun).
e) Normalisation
Les entrées et sorties sont standardisées avec moyennes et écarts-types par canal, calculés sur les 85 graphes d'entraînement. Chaque cas porte en plus un facteur d'échelle par champ (proportionnel à ) pour que le modèle travaille toujours dans un espace , quelles que soient les dimensions du conduit.
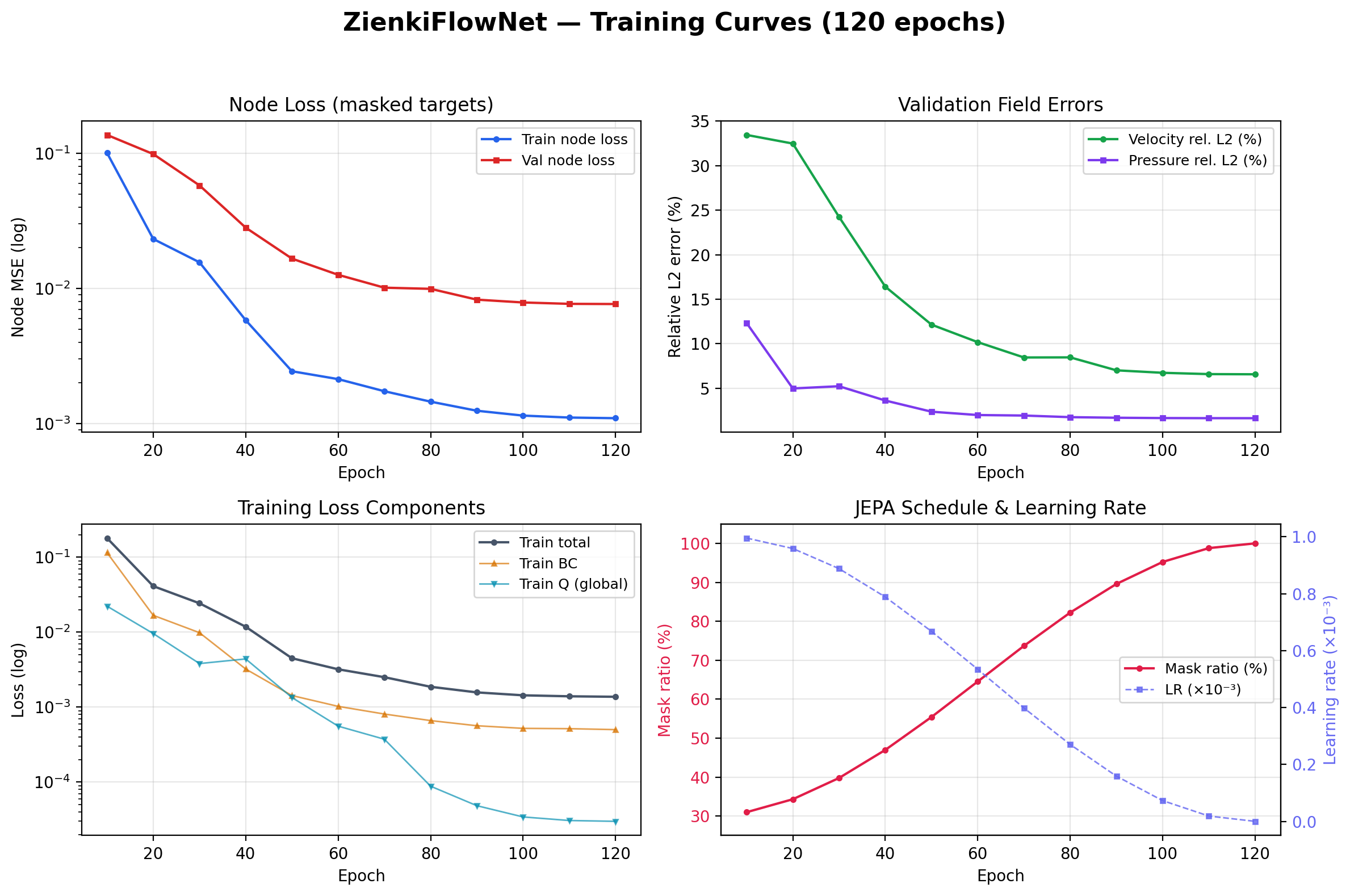
Courbes d'entraînement sur 120 époques : (haut-gauche) MSE sur les cibles masquées en train et validation, (haut-droite) erreurs L2 relatives en vitesse et pression sur la validation, (bas-gauche) composantes de la perte d'entraînement (total, BC, Q), (bas-droite) planning du masque JEPA (30 %→100 %) et learning rate avec warmup 5 époques + annealing cosinus.
6. Résultats
Performance sur les 15 cas de validation (géométries non vues) :
| Métrique | Médiane | Maximum |
|---|---|---|
| Erreur L2 relative en vitesse | 5,1 % | 17,0 % |
| Erreur L2 relative en pression | 1,7 % | 9,5 % |
| Erreur absolue sur le débit Q | 1,3 × 10⁻⁴ | — |
Points saillants :
- Erreur médiane de 5,1 % en vitesse sur des géométries diverses
- Prédiction de pression à moins de 1,7 % pour la plupart des cas
- Précision exceptionnelle sur le débit (< 0,1 % d'erreur relative)
- Pire cas en vitesse : 17 % sur la géométrie la plus complexe (case_0090 : conduit étroit avec plusieurs coudes serrés)
- Temps d'inférence : ~10 ms par cas sur CPU (contre secondes à minutes pour le solveur EF)
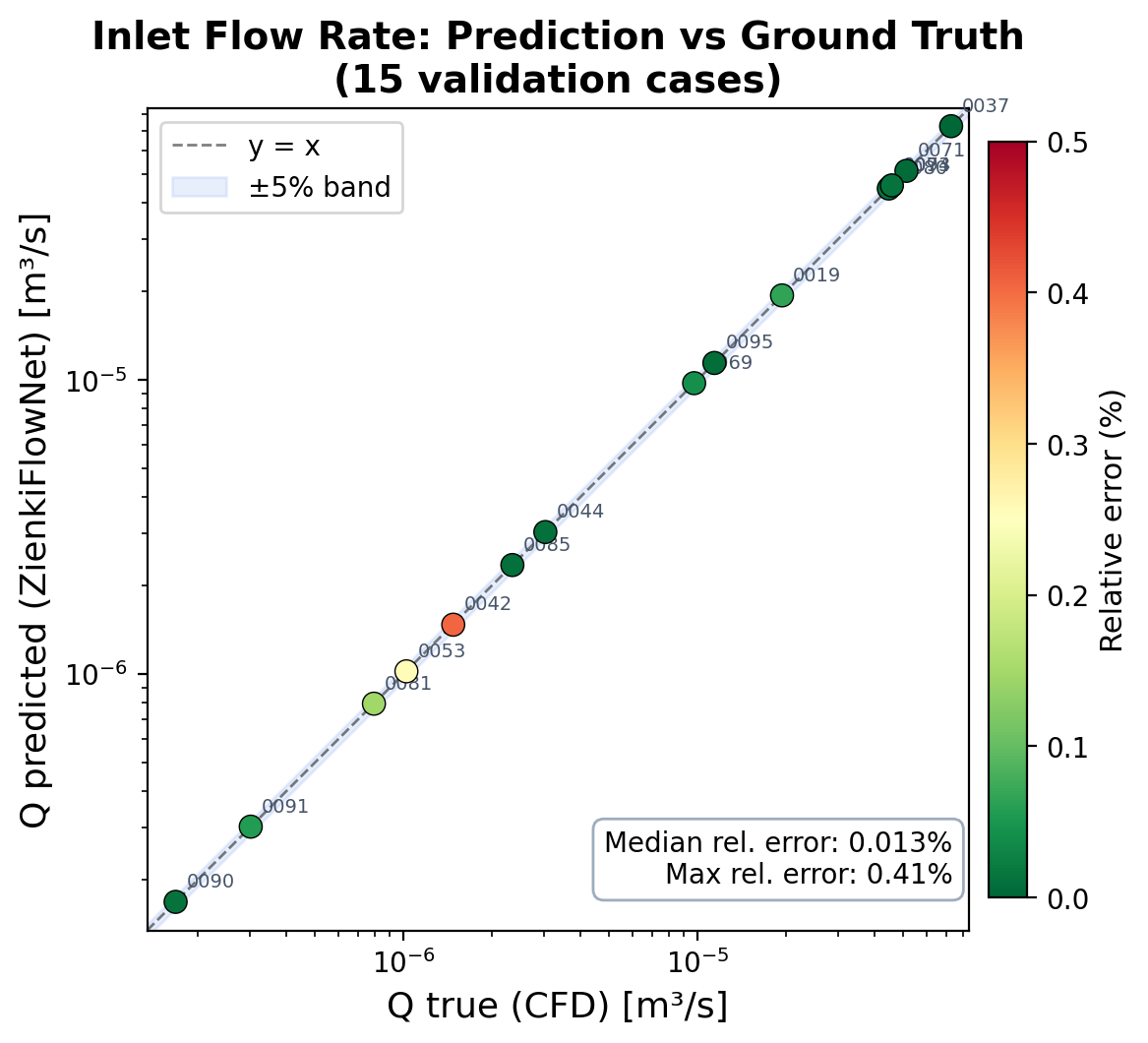
Débit prédit en entrée vs débit de référence sur les 15 cas de validation. Tous les points se placent quasiment sur la droite d'identité, confirmant la capacité du Token Query Head à extraire le scalaire global à partir des features par nœud avec une erreur relative sous-0,5 %.
7. Résultats visuels
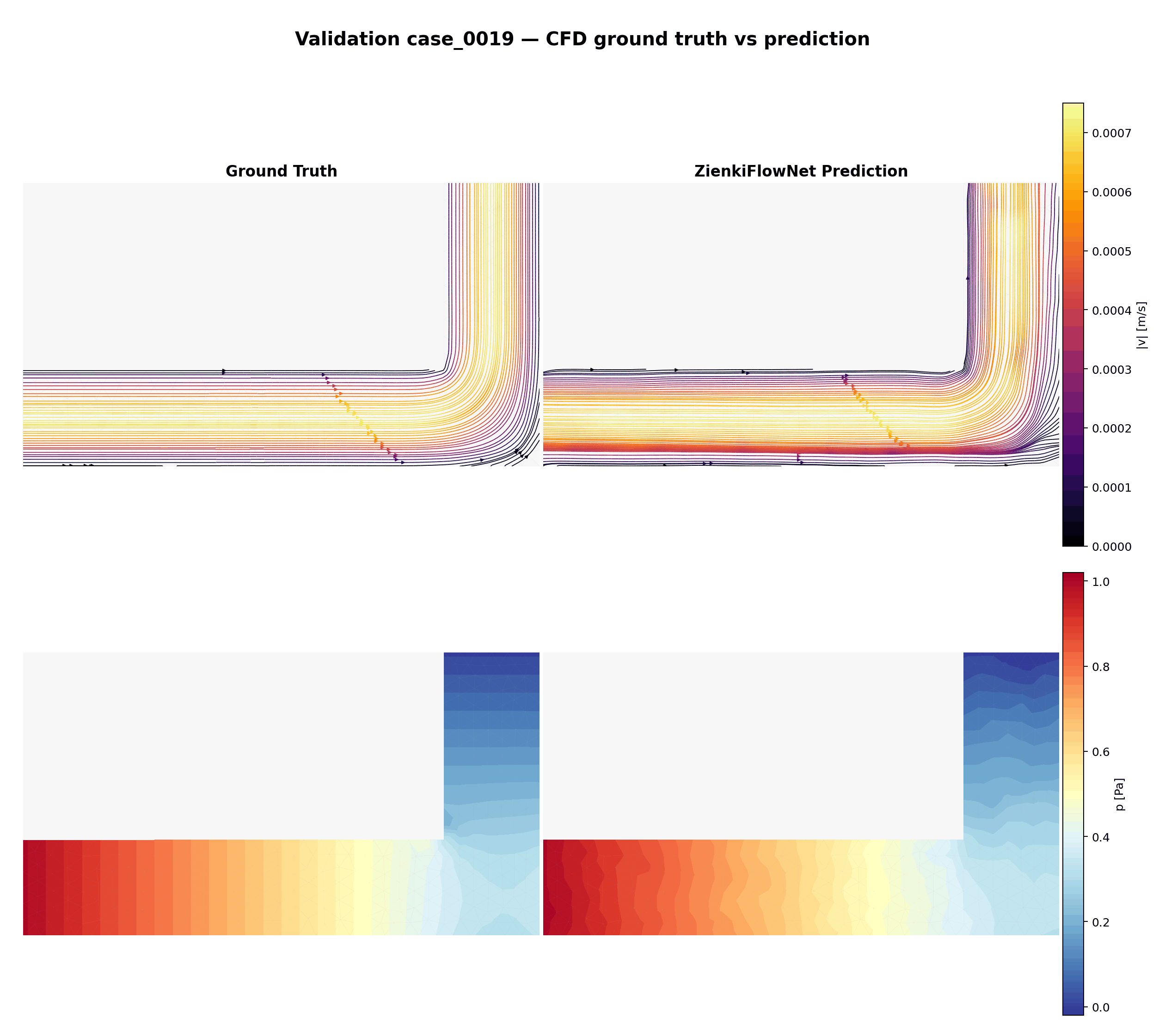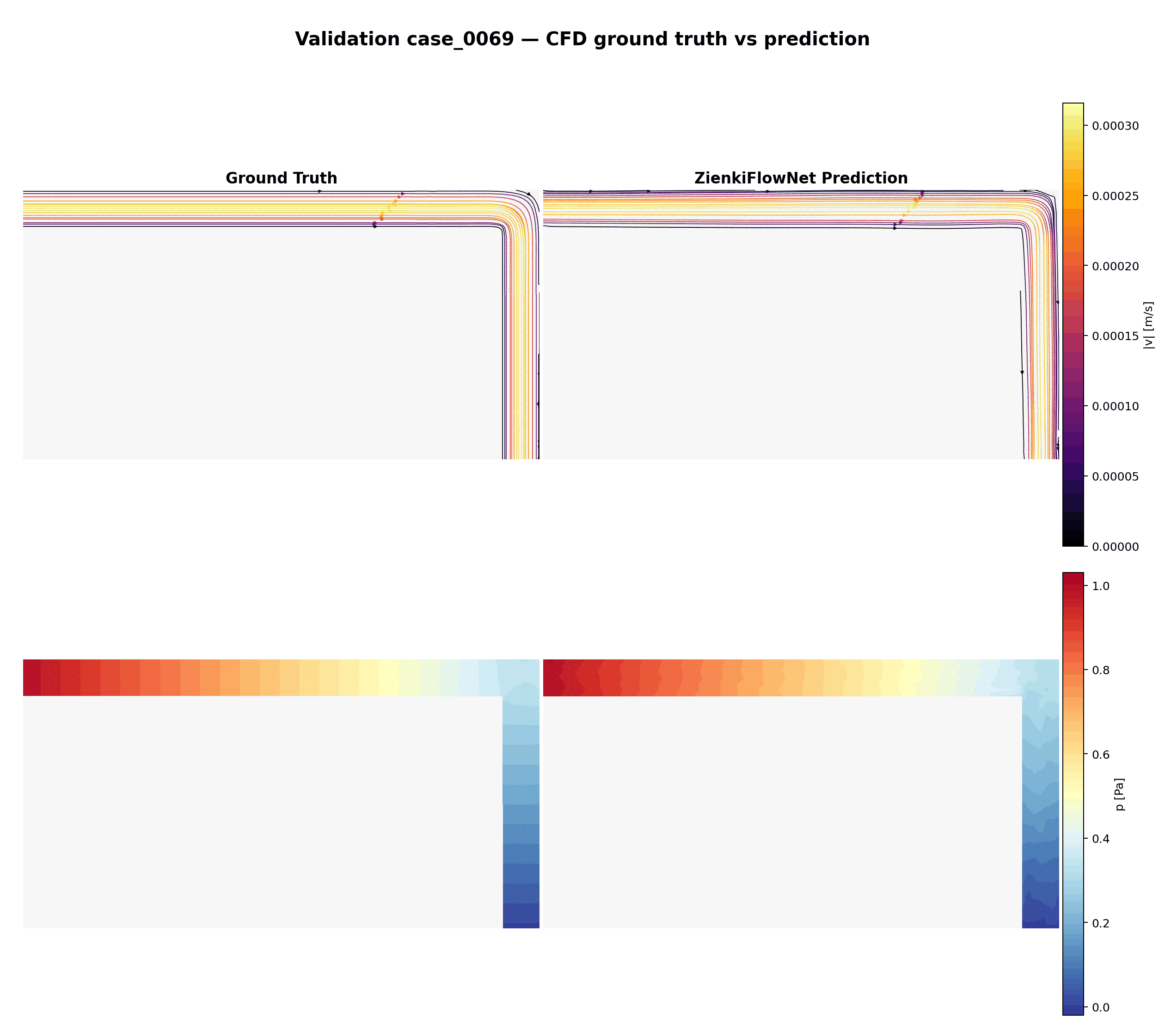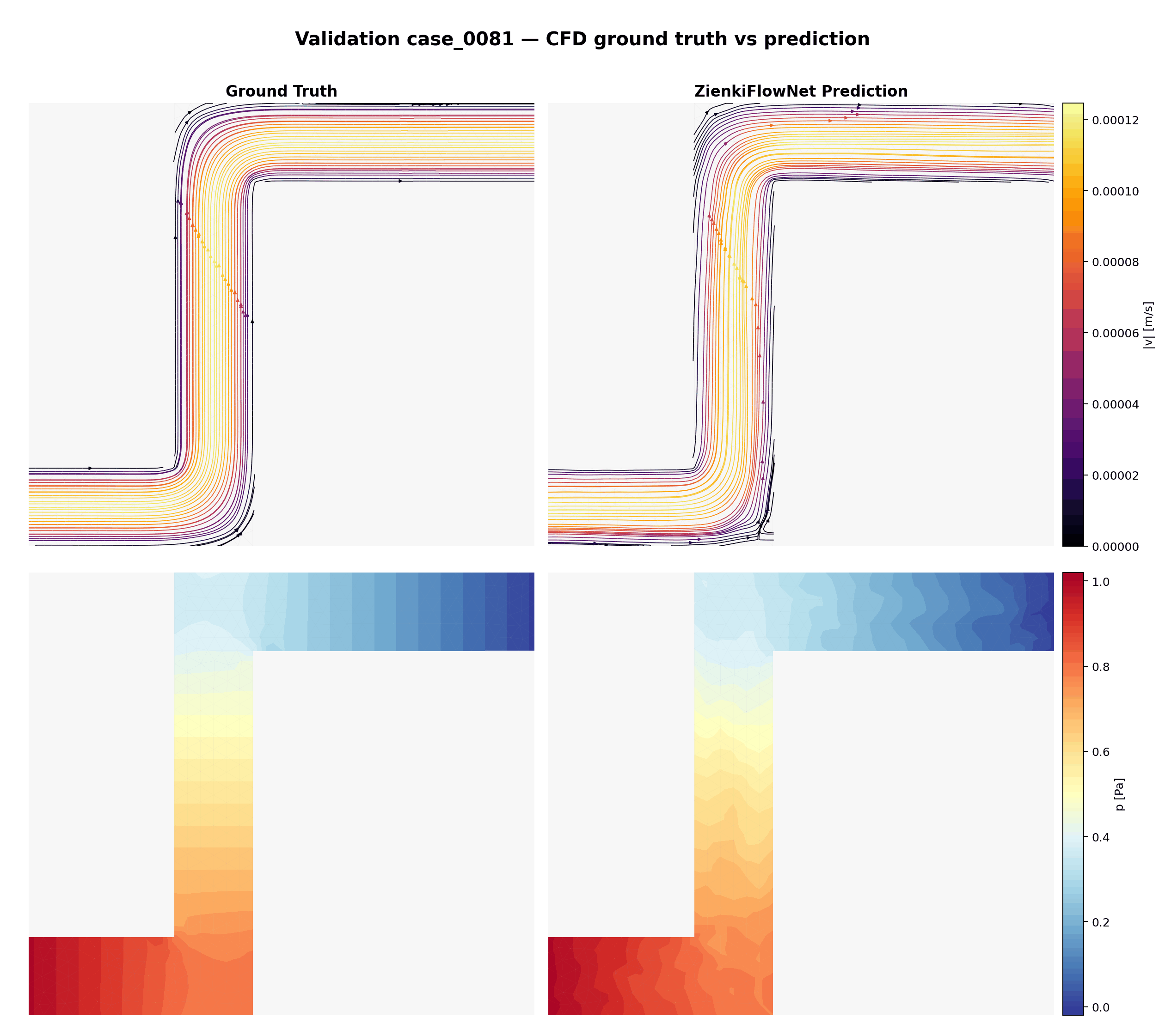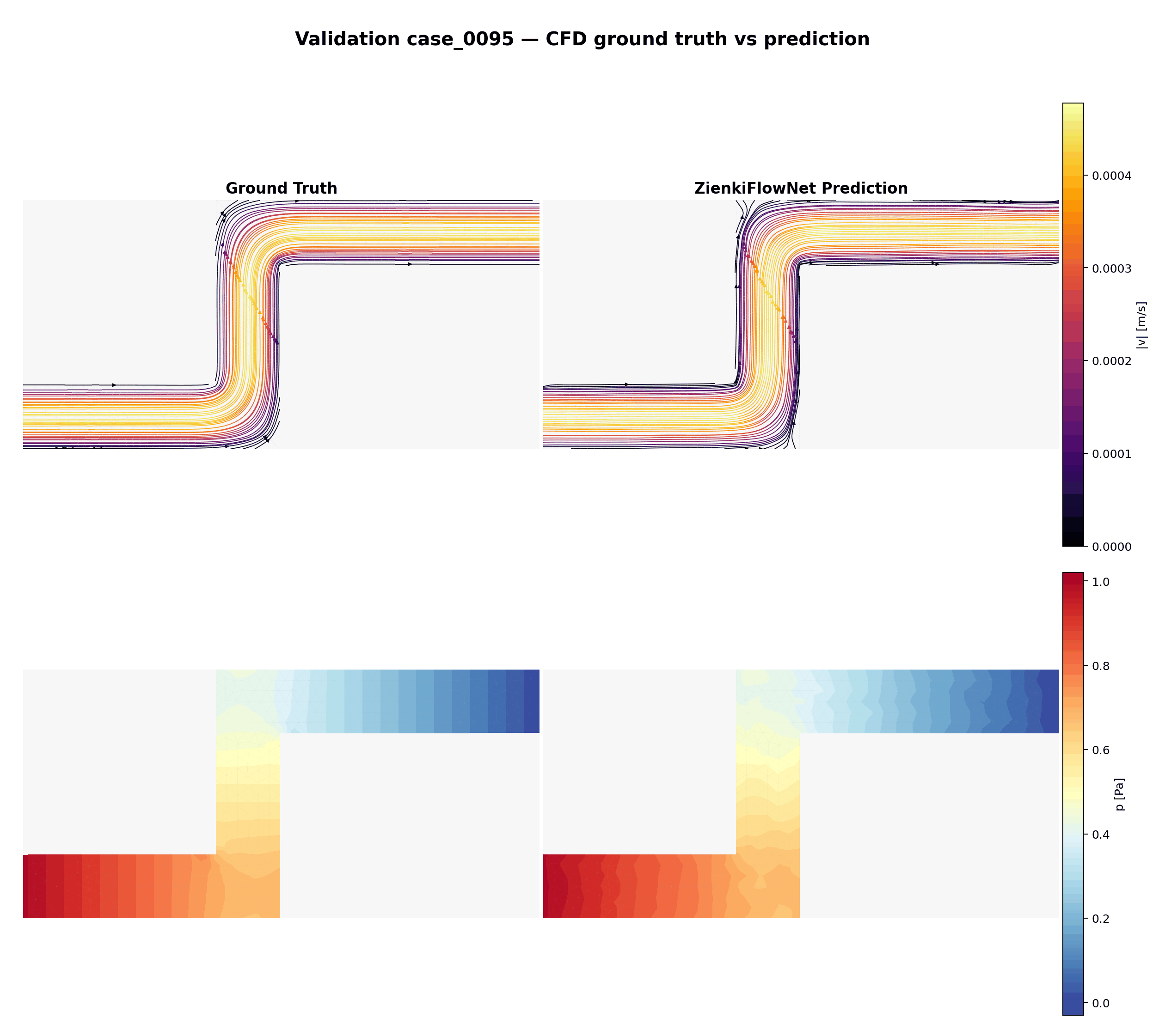
Comparaison animée entre vérité terrain (CFD) et prédictions ZienkiFlowNet sur 15 cas de validation non vus. Ligne du haut : lignes de courant colorées par magnitude de vitesse. Ligne du bas : champ de pression.

Aperçu des 85 géométries d'entraînement montrant la diversité des configurations de conduits : largeurs, longueurs et 0 à 3 coudes variables.
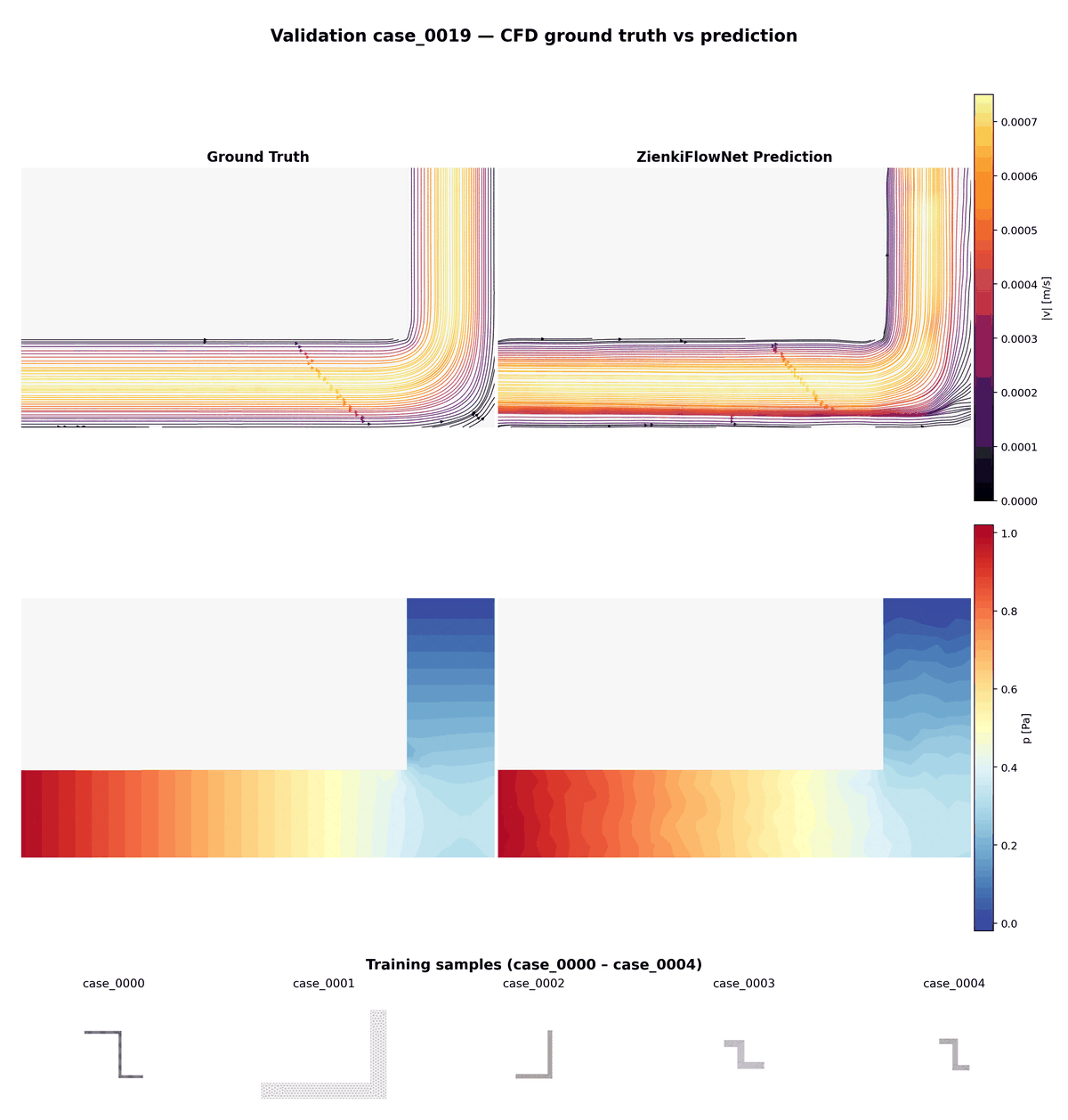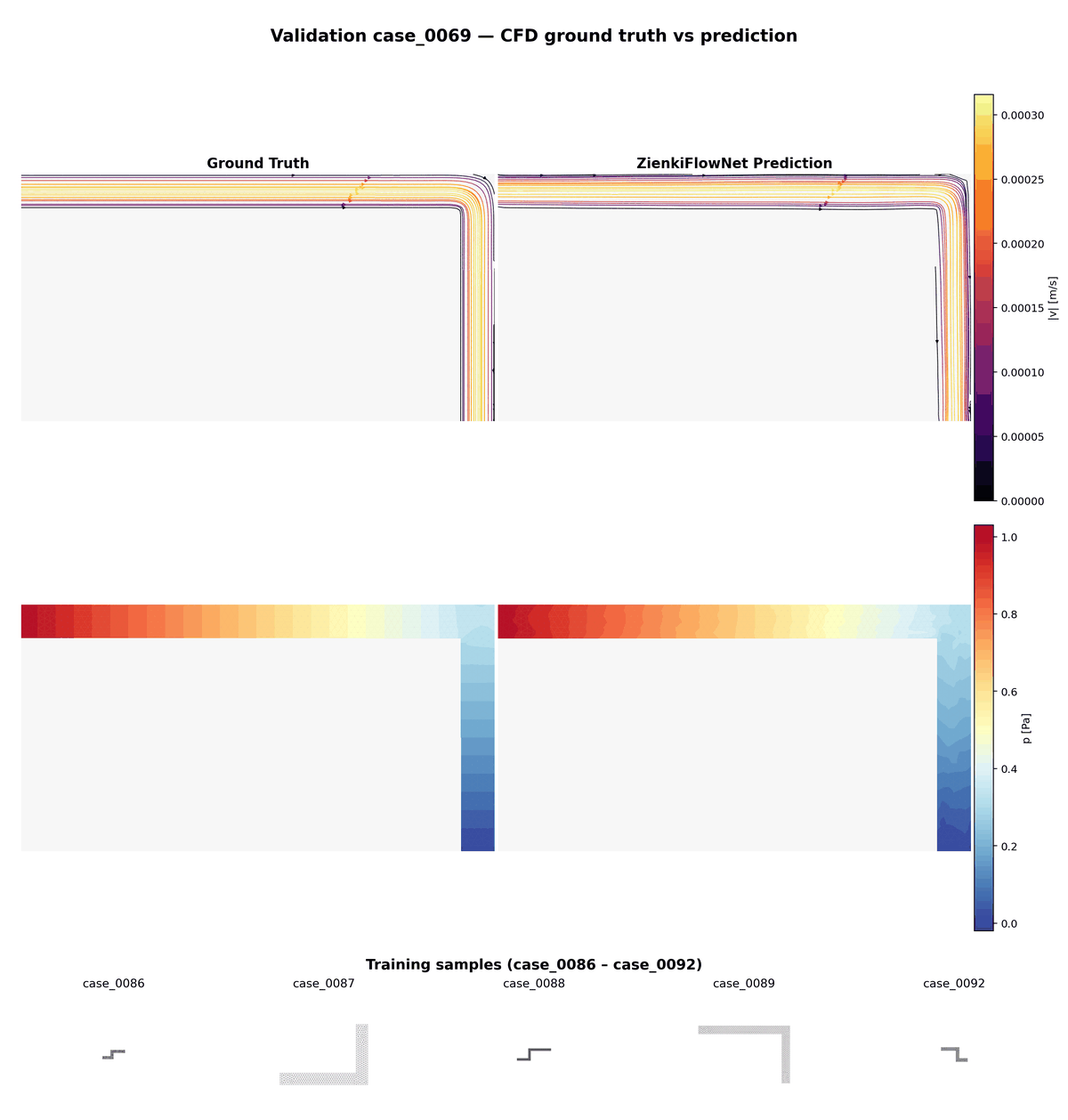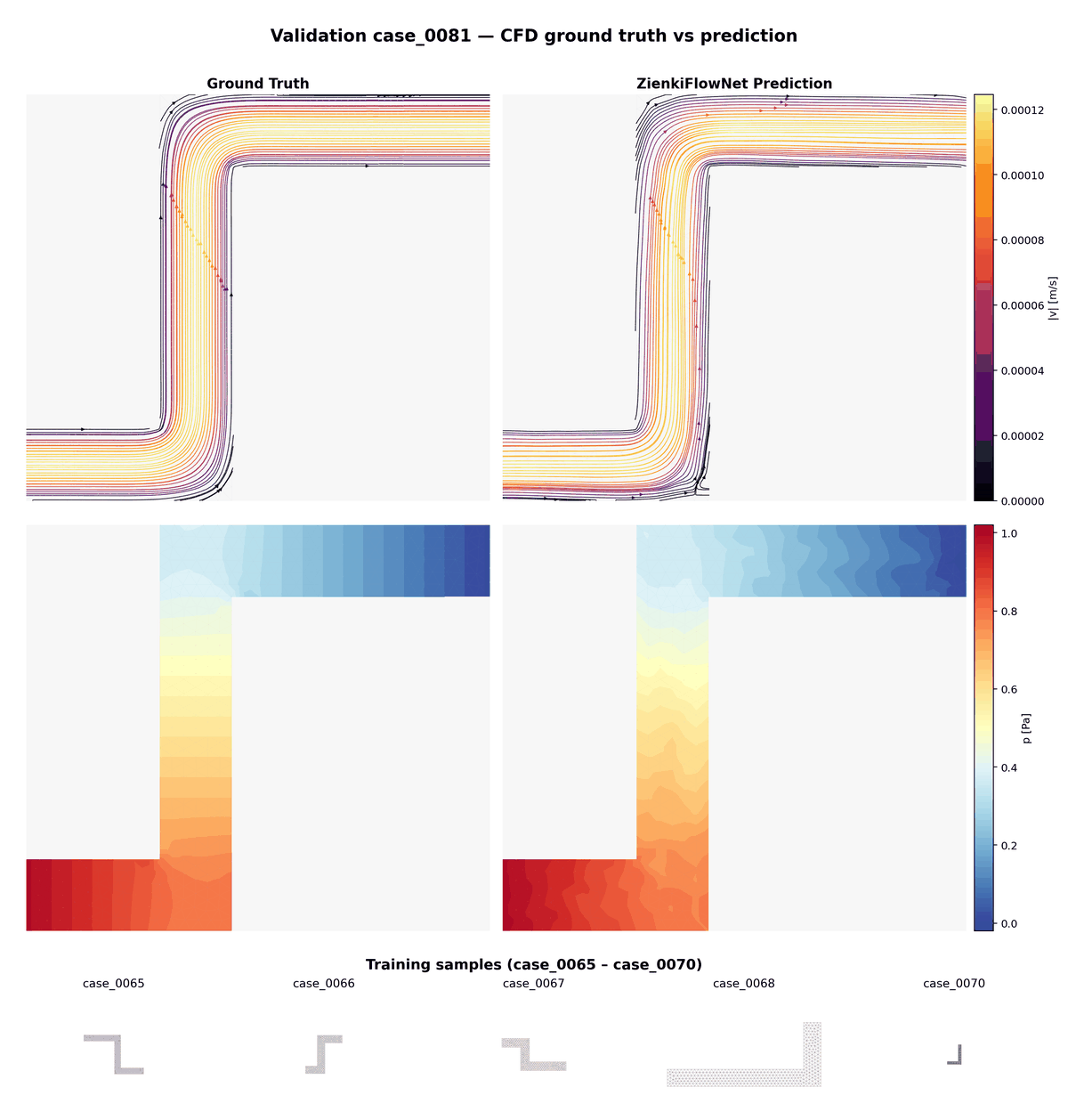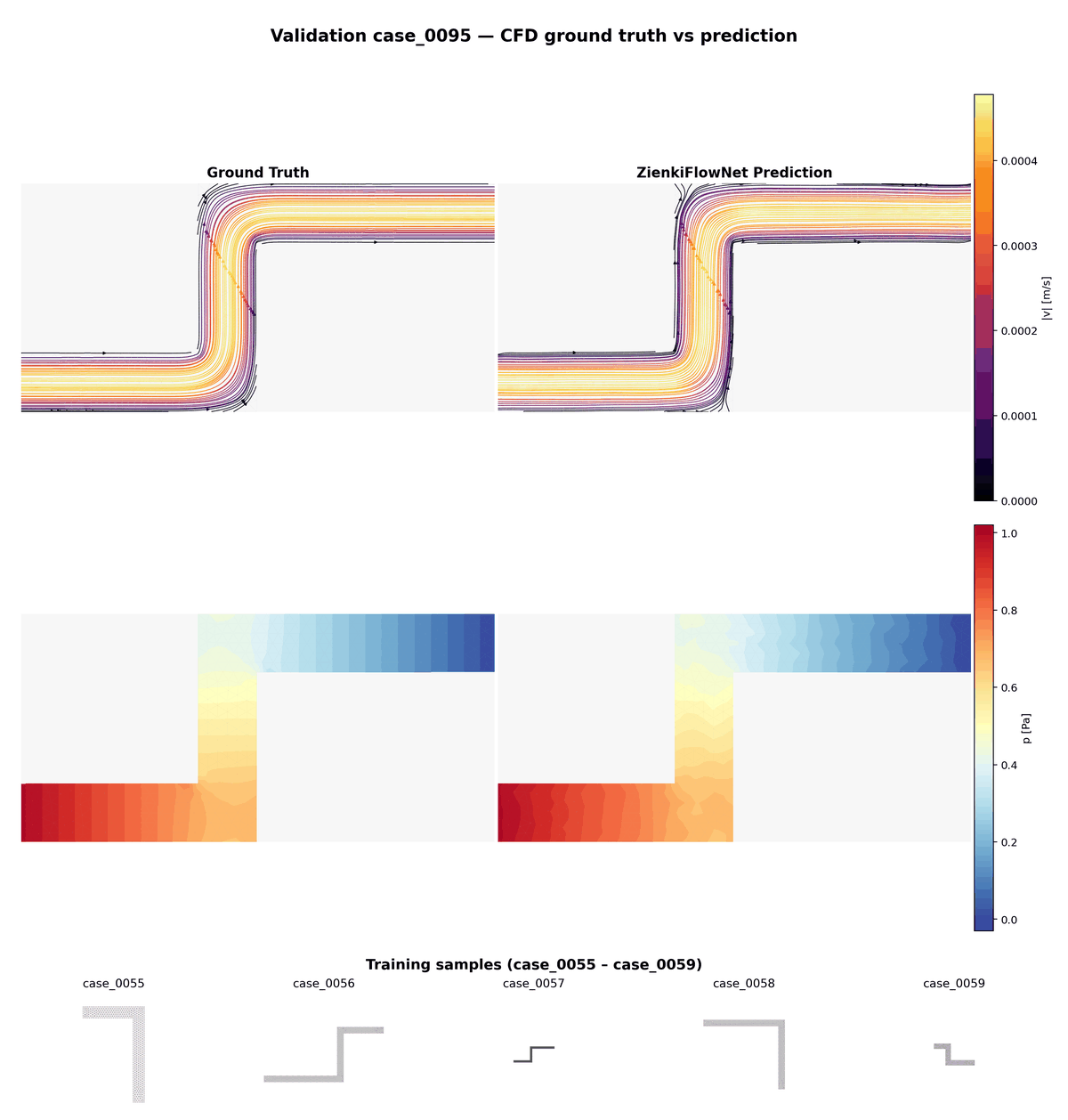
Animation combinée : comparaison validation (haut) en alternance avec les géométries d'entraînement (bas, 3× plus rapide), illustrant la variété des cas dont le modèle apprend et auxquels il généralise.
8. Conclusion
ZienkiFlowNet démontre que les réseaux de neurones sur graphes, lorsqu'ils sont dotés de biais inductifs physics-aware — passage de messages éléments-finis, encodage positionnel Laplacien, repères locaux équivariants et pertes de divergence — peuvent servir de modèles de substitution précis pour des problèmes CFD paramétriques. L'architecture double-branche sépare proprement la tâche de prédiction de champ longue portée de l'estimation scalaire sensible aux frontières, produisant des erreurs médianes inférieures à 5 % en vitesse et 2 % en pression sur des géométries de conduits non vues.
Cela ouvre la porte à l'exploration de design en temps réel : un ingénieur peut évaluer des centaines de géométries candidates dans le temps qu'il fallait auparavant pour en simuler une seule.